KV存储项目架构与开发流程详解
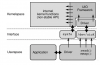
一、KV存储系统架构概述
一个典型的KV(Key-Value)存储系统通常包含以下核心组件:
- 存储引擎:负责数据的实际存储和检索
- 网络层:处理客户端请求和响应
- 协议层:定义客户端与服务端的通信协议
- 内存管理:高效的内存分配和回收机制
- 持久化模块:数据落盘和恢复机制
- 集群管理(分布式版本):节点间通信和数据分片
二、典型文件结构与分工
kv-store/
├── src/
│ ├── main.c # 程序入口,初始化各组件
│ ├── storage/
│ │ ├── engine.c # 核心存储引擎实现
│ │ ├── memtable.c # 内存表结构
│ │ ├── sstable.c # 磁盘上的排序字符串表
│ │ └── compaction.c # 压缩合并策略
│ ├── network/
│ │ ├── server.c # 网络服务主循环
│ │ ├── connection.c # 连接管理
│ │ └── protocol.c # 协议解析与封装
│ ├── utils/
│ │ ├── hash.c # 哈希函数实现
│ │ ├── bloom_filter.c # 布隆过滤器实现
│ │ └── lru_cache.c # LRU缓存实现
├── include/ # 头文件目录
└── tests/ # 单元测试目录
三、核心组件详解
1. 存储引擎组件
MemTable (内存表)
- 功能:在内存中维护有序的键值对,通常使用跳表(SkipList)或平衡树实现
- 关键操作:
put(key, value)- 插入/更新键值对
get(key)- 查找指定键的值
- 溢出机制:当MemTable大小超过阈值,转为Immutable MemTable并开始写入SSTable
SSTable (Sorted String Table)
- 功能:磁盘上的不可变有序键值文件
- 结构特点:
- Data Blocks: 实际数据块
- Data Blocks: 实际数据块
- Index Block: key到data block位置的索引
- Bloom Filter:快速判断key是否存在
Compaction (压缩合并)
- 作用:减少SSTable数量,清理过期数据,提高查询效率
- 策略: Leveled或Tiered compaction策略
WAL (Write-Ahead Log)
- 目的:保证数据持久性和崩溃恢复能力
##四、网络层组件
Server模块
1.事件循环(event loop)处理客户端连接
2.IO多路复用(epoll/kqueue)管理大量并发连接
Protocol模块
1.支持多种协议如Redis协议/resp或自定义二进制协议
2.请求解析与响应封装
##五、开发流程建议
1.基础版本开发流程:
graph TD;
A[设计内存数据结构]-->B[实现基本CRUD操作];
B-->C[添加WAL日志];
C-->D[设计磁盘存储格式];
D-->E[实现SSTable读写];
E-->F[添加Compaction逻辑];
F-->G[集成网络接口];
2.性能优化阶段:
1)基准测试找出瓶颈点
2)针对热点路径优化(哈希算法/缓存策略等)
3)引入线程池/协程提高并发能力
3.生产级考虑:
1)完善监控指标收集
2)增加备份/恢复工具
3)压力测试与长期稳定性验证
需要加载特定组件时,可以通过构建系统的模块化设计按需初始化。例如CMake中可以单独编译链接storage模块而不依赖network部分。
内容由零声教学AI助手提供,问题来源于学员提问


![if [ -t 1 ]; then
RED=$(tput setaf 1)
GREEN=$(tput setaf 2)
YELLOW=$(tput setaf 3)
BLUE=$(tput setaf 4)
BOLD=$(tput bold)
RESET=$(tput sgr0)
else
RED=](https://linuxcpp.0voice.com/zb_users/upload/2023/05/202305162216033652866.png)
![#!/bin/bash
if [ -t 1 ]; then
RED=$(tput setaf 1)
GREEN=$(tput setaf 2)
YELLOW=$(tput setaf 3)
BLUE=$(tput setaf 4)
BOLD=$(tput bold)
RESET=$(tput sgr0)
else
RED=](https://linuxcpp.0voice.com/zb_users/upload/2023/05/202305162231282792694.png)




![if [ -t 1 ]; then
RED=$(tput setaf 1)
GREEN=$(tput setaf 2)
YELLOW=$(tput setaf 3)
BLUE=$(tput setaf 4)
BOLD=$(tput bold)
RESET=$(tput sgr0)
else
RED=](https://linuxcpp.0voice.com/zb_users/upload/2023/05/202305162232428008348.png)