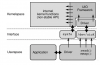
这段代码实现了一个音乐推荐系统的预测功能,使用 Django 作为后端框架,并利用 TensorFlow 构建神经网络模型。下面是对各个部分的详细解释:
1. 环境和依赖
import os
import django
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Flatten, Dense, Concatenate
from django.db.models import Max
import logging
# 配置日志记录
logging.basicConfig(level=logging.INFO)
# 配置 Django 环境
os.environ.setdefault('DJANGO_SETTINGS_MODULE', '音乐推荐系统.settings')
django.setup()
- 导入库:引入了必要的库,包括
os、django、numpy和tensorflow。 - 配置 Django 环境:设置并初始化 Django 项目的环境,以便能够使用 Django 的 ORM(对象关系映射)来访问数据库。
2. 导入Django模型
# 导入 Django 模型
from music.models import Song, SongSheet, SongType
from user.models import User, RateSong
- 从定义的 Django 应用中导入模型,例如用户、歌曲及其评分信息。
3. 定义预测函数 predict
def predict(user_id_to_predict):
try:
# 加载数据
commentList = RateSong.objects.all()
user_ids = [x.user_id for x in commentList]
item_ids = [x.song_id for x in commentList]
ratings = [x.rate for x in commentList]
# 检查数据是否为空
if not user_ids or not item_ids:
logging.error("No data found in RateSong model.")
return []
- 加载数据:从数据库中读取所有用户评分信息(即
RateSong表中的数据)。 - 将用户 ID、歌曲 ID 和评分存储到相应的列表中。
- 检查这些列表是否为空,如果没有数据则记录错误并返回空列表。
4. 构建深度学习模型
num_users = max(user_ids) + 1
num_items = max(item_ids) + 1
# 定义模型结构...
output = Dense(num_items, activation='softmax')(dense2)
model = Model(inputs=[user_input, item_input], outputs=output)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
- 计算用户和物品数量:得到唯一用户数和物品(歌曲)数。
- 构建嵌入层:使用 Keras 的 API 来定义输入层、嵌入层、连接层和输出层,以创建一个用于推荐系统的神经网络。
- 编译模型:选择优化器为 Adam,并指定损失函数和评估指标。
5. 训练模型
# 训练模型
model.fit([np.array(user_ids), np.array(item_ids)], np.array(ratings), epochs=20, batch_size=2)
- 使用收集的数据对模型进行训练,通过将用户 ID 和物品 ID 转换成 NumPy 数组并传递给
model.fit()函数进行训练。
6. 做出预测
# 预测
if user_id_to_predict < num_users:
inputs = np.array([user_id_to_predict])
predictions = model.predict([inputs, np.zeros_like(inputs)])
num_recommendations = 8
top_item_indices = np.argsort(predictions.flatten())[-num_recommendations:][::-1]
resultList = []
songList = Song.objects.all()
for top_item_id in top_item_indices:
for song in songList:
if top_item_id == song.songId:
resultList.append(song)
return resultList
- 根据传入的
user_id_to_predict参数进行预测。如果该用户存在于已知用户中,就生成输入数组,并调用model.predict()得到可能喜欢的歌曲概率。 - 找到概率最高的几首歌,然后在数据库中查询对应的信息并返回结果。
总结
整个过程可以概括为:
- 从数据库中加载已有的数据(用户评分)。
- 利用这些数据构建和训练一个推荐模型。
- 根据特定用户做出歌曲推荐,并将结果返回。
最后一行代码:
if __name__ == '__main__':
print(predict(1))
表示如果这个文件被直接执行,则会调用 predict 函数,并传入一个示例用户 ID(这里是 1),输出该用户可能感兴趣的推荐歌曲。
内容由零声教学AI助手提供,问题来源于学员提问




![num_users = max(user_ids) + 1
num_items = max(item_ids) + 1
# 定义模型结构...
output = Dense(num_items, activation='softmax')(dense2)
model = Model(inputs=[user_input, item_input], outputs=output)
model...](https://linuxcpp.0voice.com/zb_users/upload/2023/05/202305162234068218239.png)