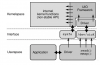
SPDK(Storage Performance Development Kit)是一个开源的存储开发工具包,旨在提供高性能、低延迟的存储应用程序。SPDK 主要用于实现与 NVMe 存储设备的高效交互,但它也可以用于处理网络流量和全流量报文。
如果你想使用 SPDK 来处理网络流量的全量存储报文,可以考虑以下几个方面:
1. 架构设计
- 数据接收: 使用 DPDK(Data Plane Development Kit)来处理网络流量。这是一种快速的数据平面处理库,可以通过用户态驱动访问网络接口,以实现高速包处理。
- 存储层: 结合 SPDK 与 NVMe SSD,利用其异步编程模型,实现低延迟和高吞吐量的数据写入。
2. 技术栈
DPDK:
- 用于快速接收和转发网络数据包。
- 支持多核并行处理,可以充分利用多核 CPU 的计算能力。
SPDK:
- 提供了高性能的 NVMe 驱动,使得数据能够以非常低的延迟写入 NVMe SSD。
- 支持异步 I/O 操作,这对于高吞吐量应用尤其重要。
3. 工作流程
初始化环境:
- 配置 DPDK 和 SPDK,确保它们正确安装并能够相互协作。
- 初始化网卡,并配置接收队列。
捕获网络报文:
- 使用 DPDK API 接收实时流量包,可以选择对感兴趣的特定协议或端口进行过滤。
解析和处理报文:
- 对捕获到的数据包进行解析,提取出关键信息或进行必要的数据清洗。
数据存储:
- 将解析后的报文通过 SPDK 异步 I/O 写入 NVMe SSD。在这一过程中,利用 SPDK 的优化技术来提高存储性能,例如批量提交等。
监控与调优:
- 实时监控系统性能,包括 CPU 利用率、I/O 延迟及带宽等,并根据需要调整参数以优化系统表现。
4. 示例代码
下面是一个简化的伪代码示例,以帮助理解如何将 DPDK 和 SPDK 一起使用:
#include <dpdk/rte_ethdev.h>
#include <spdk/nvme.h>
void process_packet(struct rte_mbuf *mbuf) {
// 数据包解析逻辑
}
void store_data_to_nvme(void *data, size_t len) {
struct spdk_nvme_ns *ns = ...; // 获取命名空间
spdk_nvme_ns_cmd_write(ns, ..., data, len, NULL);
}
int main() {
// 初始化 DPDK
rte_eal_init(argc, argv);
// 初始化 SPDK
spdk_env_init(...);
while (running) {
struct rte_mbuf *mbuf;
// 从 DPDK 接收队列中获取数据包
mbuf = receive_packet();
if (mbuf) {
process_packet(mbuf);
store_data_to_nvme(mbuf->data_ptr, mbuf->data_len);
rte_pktmbuf_free(mbuf); // 不要忘记释放内存
}
}
return 0;
}
注意事项:
- 性能调优:对不同负载下进行基准测试,根据实际需求不断调整参数,以找到最佳性能设置。
- 错误处理:确保在生产代码中适当检查错误,并实施必要的异常管理机制,以防止数据丢失或系统崩溃。
- 硬件支持:确保你的硬件(网卡、SSD)支持所需功能,并具备足够性能满足系统要求。
通过合理使用 DPDK 和 SPDK,你可以构建一个强大的、高效能的全流量报文存储解决方案。
内容由零声教学AI助手提供,问题来源于学员提问






![r: passing 'const pid_control::DbusPidZone' as 'this' argument discards qualifiers [-fpermissive]
| 419 | current("MISSNIC25G");
| | ~~~~~~~^~~~~~~~~~~~~~](https://linuxcpp.0voice.com/zb_users/upload/2023/05/202305162216033652866.png)